0x01 爬虫
爬虫是一种自动化获取网络信息的程序。Scrapy是python实现的著名的爬虫框架。以前实现过一些简单的爬虫项目,用以获取特定信息。我做的爬虫基于两个模块,一是目标解析获取、二是站点页面解析,通过解析初始页面向消费者队列中添加需要爬取得url,页面解析模块则从队列中拉取url解析并存储数据。这是最基本的爬虫模型,看起来可扩展性差了很多。最近没有什么开发项目,便熟悉下scrapy框架,学习优秀的产品,做低调的魔法师。
0x02 Scrapy Tutorial
最初接触Scrapy,觉得思路还是特别凌乱。其指南中介绍了简单的使用方法。
首先可以使用scrapy命令行中的scrapy startproject [project name]创建你自己的scrapy项目。scrapy会自动为你生成类似下面的目录结构。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
...
在spider目录中,你可以编写自己的爬虫模块,例如dmoz_spider.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz" # 名字是每个爬虫必须的,scrapy框架会根据你选择的爬虫名字寻找要启动的项目
allowed_domains = ["dmoz.org"]
start_urls = [ #这里是爬虫的起点,定义了起始爬取url
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response): #默认处理访问start_urls后返回内容的函数
filename = response.url.split("/")[-2] + '.html'
with open(filename, 'wb') as f:
f.write(response.body)
然后,第一个爬虫就做好了,最初可以使用scrapy命令行中scrapy crawl [spider name]也就是scrapy crawl dmoz运行第一个爬虫,他会讲访问start_urls之后的内容解析,并将内容写入到一个文件中。
当然这并不能满足我日常工作的需求,检索scrapy的文档,通篇思路顺序有些混乱,记录下自己的思路,是放下寂寞。
0x03 Deepen Scrapy
官方给出的框架图是这个样子的: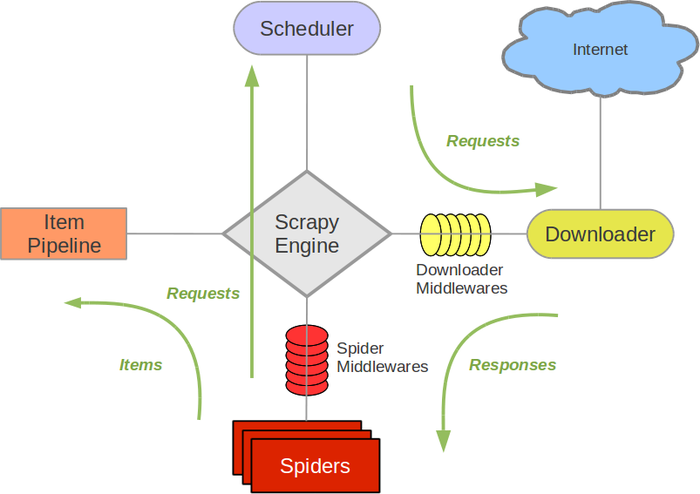
1.Scrapy Engine是用来控制数据流向,触发特定事件;
2.Scheduler中存放着需要访问的目标urls,更像是生产者与消费者中的消费队列;
3.Downloader从Scheduler中提取url并访问目标页面,返回访问结果;
4.Spider接受Downloader返回的结果,解析后返回Item或者一个新的访问请求;
5.Item Pipeline数据输出管道,接受spider返回的Item,对其做适当处理。
整体数据流向是,Engine处理最初的访问请求,并使用parse方法将需要的请求提交到schedule,Downloader定时从Scheduler中取出目标进行访问,期间数据流入Downloader Middlewares,在下载器中间件可以根据request的情况处理访问头(使用process_request(request, spider)方法)、甚至直接返回一个response对象,跳过Downloader直接流出下载器中间件,执行process_response(request,response,spider)方法,至此产出的response流到Spider Middlewares中间件,这个中间件主要对返回的结果进行搜集、解析并进行相应的处理。期间数据流经Spider产生最后的结果或者新的requests。
需要特别注意的是,每个中间件都有流入流出两个方向,处理着不同的访问需求,细分如下:
- 下载器流入:通常用于处理请求头的修改;
- 下载器流出:通常用于修改返回结果、检查返回状态码重新提交请求;
- 爬虫流入:通常用于检查返回状态,记录并抛出异常;
- 爬虫流出:通常用于解析完成后的异常处理,可以返回response、request或者异常。
0x04 Demo
使用Scrapy实现的煎蛋爬虫,一个随机代理随机UA的爬虫。
详细教程以后再写吧